Bloom Filter는 자료 구조중의 하나로, 다음 두 가지 동작이 가능합니다.
- 1. 삽입: 값을 테이블에 추가
- 2. 확인: 어떠한 값이 테이블 안에 존재하는지 확인
즉, 테이블 안에 값이 들어있는지 확인하는 것에 사용하는 간단한 자료구조지만,
삽입과 확인 과정이 특수한 방법을 가지고 있어서 몇 가지 특징들을 가집니다.
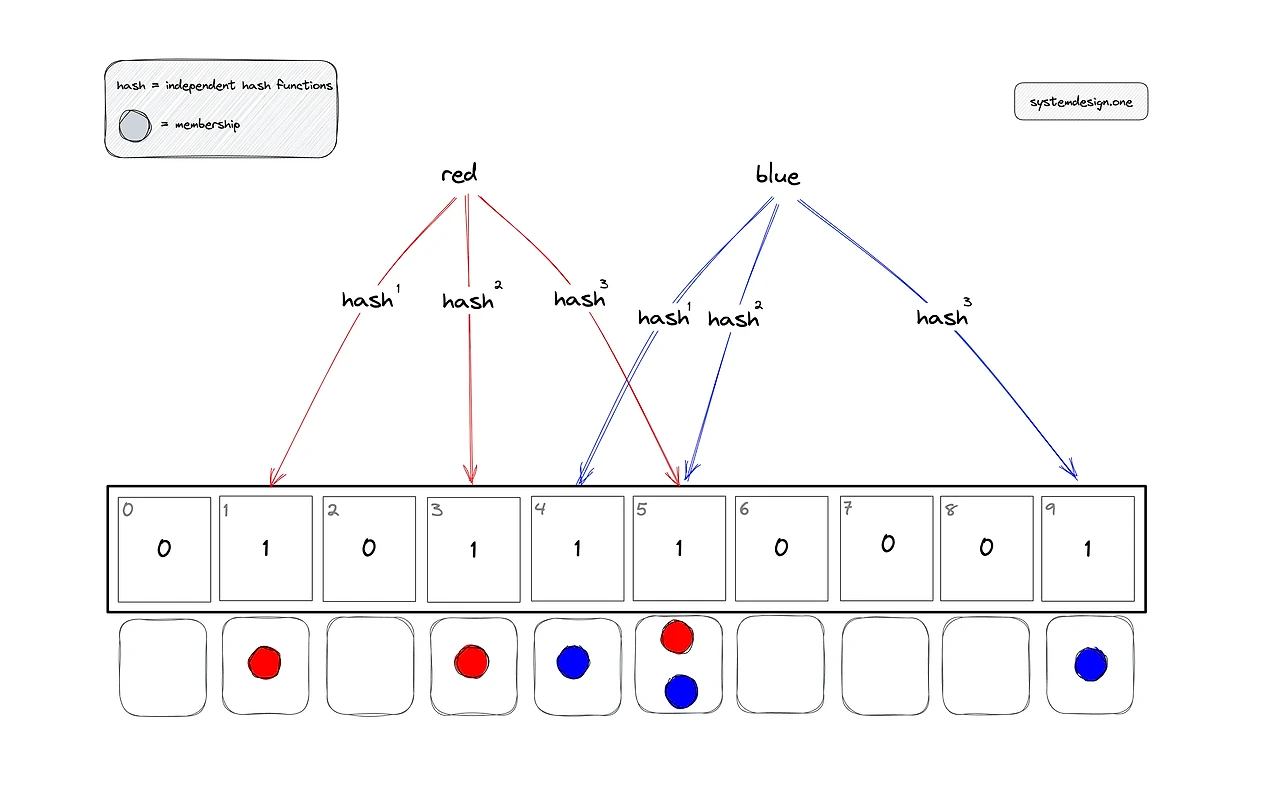
블룸 필터는 이러한 모습을 가집니다.
사진은 red와 blue라는 값을 테이블에 추가하는 과정인데,
- 1. 추가하려는 값을 해시 함수에 넣고
- 2. 나온 해시 값에 대응되는 테이블 인덱스를 1로 만든다
이 과정을 하나의 값을 추가할 때마다 3개의 해시 함수에 대하여 실행하는 모습입니다.
우리는 이 사진으로 블룸필터의 특징을 알 수 있습니다.
- 1. 테이블의 크기는 값들의 크기와 상관없이 불변하다.
- 2. 해시 함수를 쓰니 해시 충돌이 일어날 가능성이 있다.
- 3. 테이블에 추가한 값을 삭제할 수는 없다. (해시 값은 무한하지만 배열 공간은 유한하기에 해시에 대응되는 위치가 겹칠 가능성 존재)
그래서 블룸 필터를 쓸 때는 다음을 고려합니다
- 1. 테이블에 존재하지 않는 값도 존재한다고 하는 거짓 양성(false positive) 이 나올 수 있다.
- 2. 테이블에 존재하는 값은 반드시 존재한다고 말한다
1번이 가장 중요합니다.
블룸 필터는 데이터가 없어도 있다고 하는 거짓 양성(false positive) 가능성이 높기 때문에, false positive가 일어나도 괜찮은 곳에만 사용할 수 있습니다.
그럼 굳이 이런 위험성을 가지면서 이 자료 구조를 사용하는 이유가 뭘까요?
그 이유는 바로 공간과 시간 두 면에서 압도적인 가성비를 보여주기 때문입니다.
블룸 필터의 장점
공간 효율성 (메모리 사용량이 매우 적다)
일반적으로 어떤 값의 존재 여부를 확인하려면, 그 값들을 모두 저장하고 있어야 합니다.
예를 들어 100만 개의 사용자 id를 저장한다면, 100만 개의 id를 담을 수 있는 큰 저장 공간이 필요할 겁니다.
하지만 블룸 필터는 값 자체를 저장하는 것이 아니라, 테이블에서 해시 값에 해당하는 특정 위치만 1로 바꾸는 방식으로 동작합니다.
따라서 수백만 개의 데이터를 저장하더라도 테이블의 크기는 변하지 않습니다.
시간 효율성 (삽입과 확인이 매우 빠르다)
값을 확인하는 과정도 마찬가지입니다. 해시 함수를 k번 계산하고, 배열의 k개 인덱스에 접근하면 끝입니다.
이 연산 속도는 블룸 필터에 저장된 데이터의 양과 관계없이 항상 일정합니다. 테이블에 값이 1개가 있든 1억 개가 있든, 확인에 걸리는 시간은 거의 동일합니다.
정말 가슴 설레는 효율이 아닐 수 없습니다.
- m=블룸 필터 배열 크기
- k=해시 함수 개수
- n=삽입된 데이터 개수
공간 복잡도는 배열의 크기에만 의존하므로 O(m)
시간 복잡도는 해시 함수의 개수에만 의존하므로 O(k)입니다.
사실 시간 효율만 보면 해시맵도 O(1)로 상수긴 하지만,
자료 구조의 공간 복잡도가 고정된 경우는 거의 없기 때문에 블룸 필터는 확실한 장점이 있습니다.
여기까지 들었으면 이런 생각이 드실 겁니다.
그럼 블룸 필터의 크기는 어떻게 정하는 것이 좋을까?
물론 크기는 클수록 좋습니다. 크기가 클 수록 거짓 양성이 나올 경우가 줄어들고, 정확도가 올라갈 겁니다.
하지만 그럼 블룸 필터를 쓸 이유가 없어지겠죠, 오히려 다른 자료구조보다 커질지도 모릅니다.
그래서 우리는 허용되는 오차치를 정하여 최적화 된 값들을 계산할 수 있습니다.
거짓 양성 확률 계산식
먼저, 두 가지 파라미터가 필요합니다.
- n=예상되는 삽입 데이터 개수
- p=허용 가능한 거짓 양성 오차치
이 두 가지 값으로 m,k 값을 구할 수 있는데, 그 공식은 이렇습니다.
- m = -n*ln(p) / (ln(2)^2) [비트로 표현됨]
- k = m/n * ln(2) [반올림 하면 해시 개수]
그리고 위 수식을 계산하기 쉽게 js 함수로 만들어보면,
function calculateBloomFilterParams(n, p) {
const m = - (n * Math.log(p)) / (Math.log(2) ** 2);
const k = (m / n) * Math.log(2);
const optimal_m = Math.ceil(m);
const optimal_k = Math.round(k);
return {
m: optimal_m,
k: optimal_k
};
}이렇게 나옵니다.
이것을 사용하여 몇 가지 예시를 계산해 봤습니다.

데이터가 100만 개가 있을 때 1%의 정확도를 내려면 약 1.2MB 정도의 테이블과 7개의 해시 함수만 있으면 되고,
데이터가 5만 개가 있을 때 0.1%의 정확도를 내려면 88KB의 테이블과 10개의 해시 함수만 필요합니다.
블룸 필터와 해시맵 성능 비교
성능 차이를 더 직관적으로 보기 위하여
- 블룸 필터 허용 오차치 0.1%
- 데이터당 평균 크기 15바이트
을 기준으로 데이터 개수가 커짐에 따라 해시맵과 블룸 필터의 메모리 사용량이 어떻게 커지는지 시각화해봤습니다.
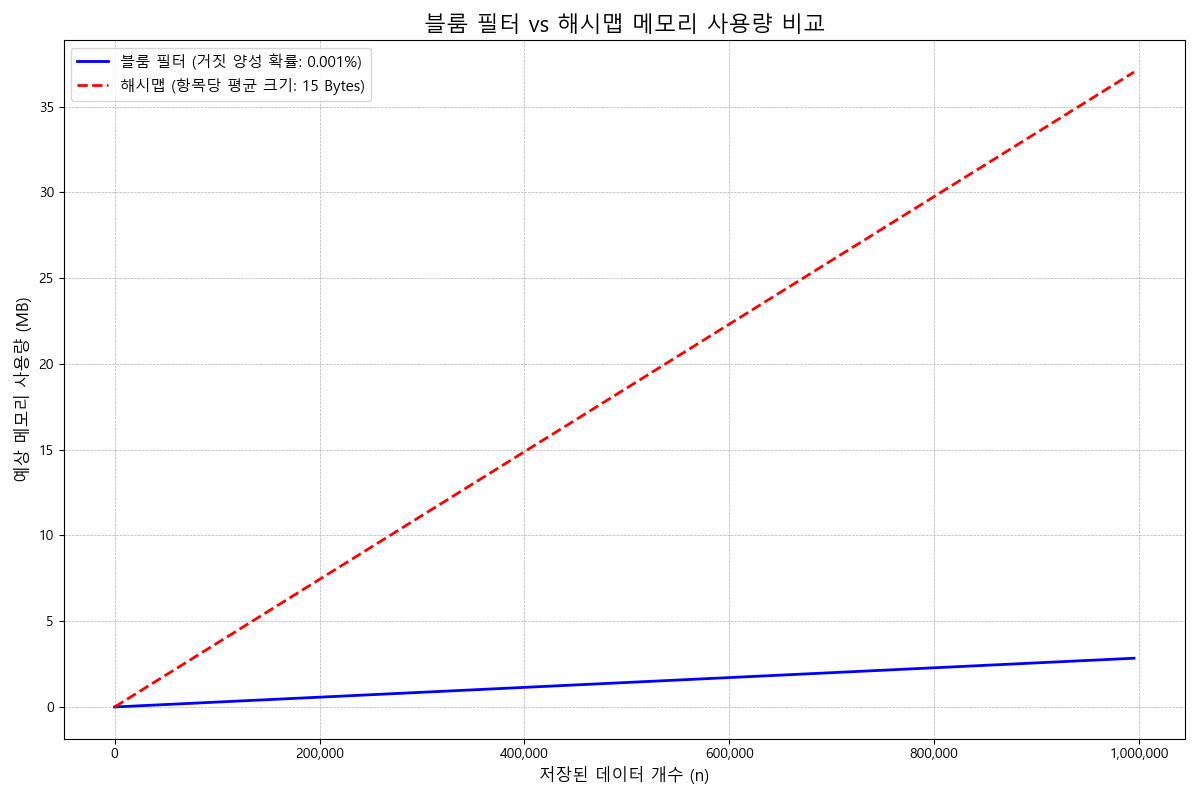
그럼 이러한 표를 볼 수 있습니다.
거짓 양성 확률이 0.001%으로 매우 낮음에도 최소 10배가 넘는 공간 효율을 보입니다.
물론, 양성 확률이 낮을수록 블룸 필터 테이블의 크기가 커지고,
테이블의 크기가 커지면 그와 비례해서 확인 및 삽입 과정에서 써야 하는 해시 함수의 개수가 많아지는 점은 인지해야 합니다.
블룸 필터 사용 사례들
대용량 데이터베이스
데이터베이스는 보통 데이터를 디스크에 저장하는데, 디스크 접근은 메모리 접근보다 훨씬 느립니다.
그래서, 어떤 데이터가 디스크에 존재하는지 확인하기 위해 매번 디스크를 읽는 것은 매우 비효율적입니다.
이때 블룸 필터를 사용하면 데이터의 존재 가능성을 빠르게 확인할 수 있겠죠.
블룸 필터에 거짓 양성은 있지만 거짓 음성(데이터가 있는데 없다고 하는 경우) 은 없기 때문에,
데이터가 존재하는지만 확인하는 용도로는 충분히 활용할 수 있겠습니다.
웹 브라우저 사이트 차단 기능
세상에 존재하는 모든 유해 사이트 URL을 해시맵으로 저장하려면 많은 공간을 필요로 할 겁니다.
대신, 유해 URL 목록을 블룸 필터에 저장하는 방식으로 용량을 많이 줄일 수 있습니다.
사용자가 특정 사이트에 접속할 때, 먼저 블룸 필터로 유해 사이트인지 빠르게 검사합니다.
여기서 거짓 양성이 발생하면 정상적인 사이트를 유해하다고 판단할 수 있지만, 그 확률을 낮게 설정할 수도 있고,
반대로 거짓 음성이 발생하여 유해 사이트를 놓치는 경우는 없으므로, 어떤 경우라도 안전한 선택이라고 생각할 수 있습니다.
결론
이렇게 블룸 필터는 놀라운 공간 가성비를 가지고, 검색 속도도 충분히 빠릅니다.
하지만 그 대가로 거짓 양성이라는 문제를 가지고 있죠.
따라서 데이터가 '확실히 없는지' 빠르게 판단하여 불필요한 작업을 줄이는 것이 중요한 상황에서
블룸필터만큼 적합한 자료구조는 없을 거라고 생각합니다.
프로그래밍을 하며 많은 자료구조를 배웠다고 생각했지만,
이렇게 참신한 자료구조를 보니 아직도 배우지 않은 많은 자료구조들이 있구나라고 생각하게 됩니다.
어떠한 상황을 만나더라도 제일 적합한 자료구조를 쓸 수 있도록 더 많이 공부해야겠습니다.
'오늘 배운것들' 카테고리의 다른 글
| 일을 시작하며 느낀 CS의 중요성 (0) | 2025.06.19 |
|---|---|
| 셀레니움 크롬 프로필 쓰는 방법/ 유튜브 네이버 로그인 없이 자동화 하는법 (2) | 2022.08.02 |
| ERD 기호 설명 (0) | 2020.04.12 |
| npm모듈 multer (0) | 2020.04.02 |